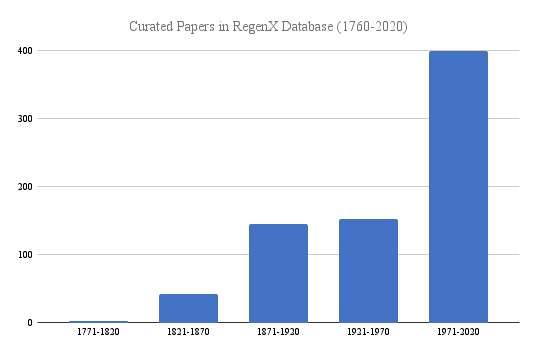
Welcome to our web-based tool. Please feel free to explore and learn more about our approach to designing our literature ontology. We used a collection of deep learning, natural language processing, and text mining techniques to optimize our models. A total of 673 research papers from 1776-2020 were collected and analyzed.
Before we could begin employing our algorithms, we needed to convert these PDF's with a wide range of quality, style, and format into machine readable text. We used Adobe's optical character recogntion to convert the documents. Then, we used regular expressions to tokenize the words in each document. We removed stopwords from each document using NLTK's stopword list. Then, we fed our documents through BioBert to create a set of "entities" and we used these as our set of startwords. We also added to this set with words from the indices of popular neural regeneration textbooks. Finally, we used the Porter stemmer on all the words to make our dictionary more robust. We also used popular data science techniques such as grid search to optimize our Dynamic Topic Model. You may feel free to interact with our model that produced the highest average topic coherence in the document upload section of this webapp. We have also included visualizations that show the plots of the topics, and the words that these topics consist of, over time in the DTM visualization section. Finally, for further analysis, take a look at the heatmaps to see analysis of the topics from an author specific perspective.
